


Today’s top AI Highlights:
-
Inflection AI founder and CEO abandons the company after raising $1.3B to join Microsoft
-
Sam Altman says the difference between GPT-5 and 4 will be the same as between GPT-4 and 3
-
Nvidia’s Project GR00T powers Apptronik’s robot to learn from human demos
-
Fireworks launches fine-tuning service – Rapidly iterate on quality and scale to production
-
Load and prompt multiple local LLMs simultaneously with LM Studio
& so much more!
Read time: 3 mins
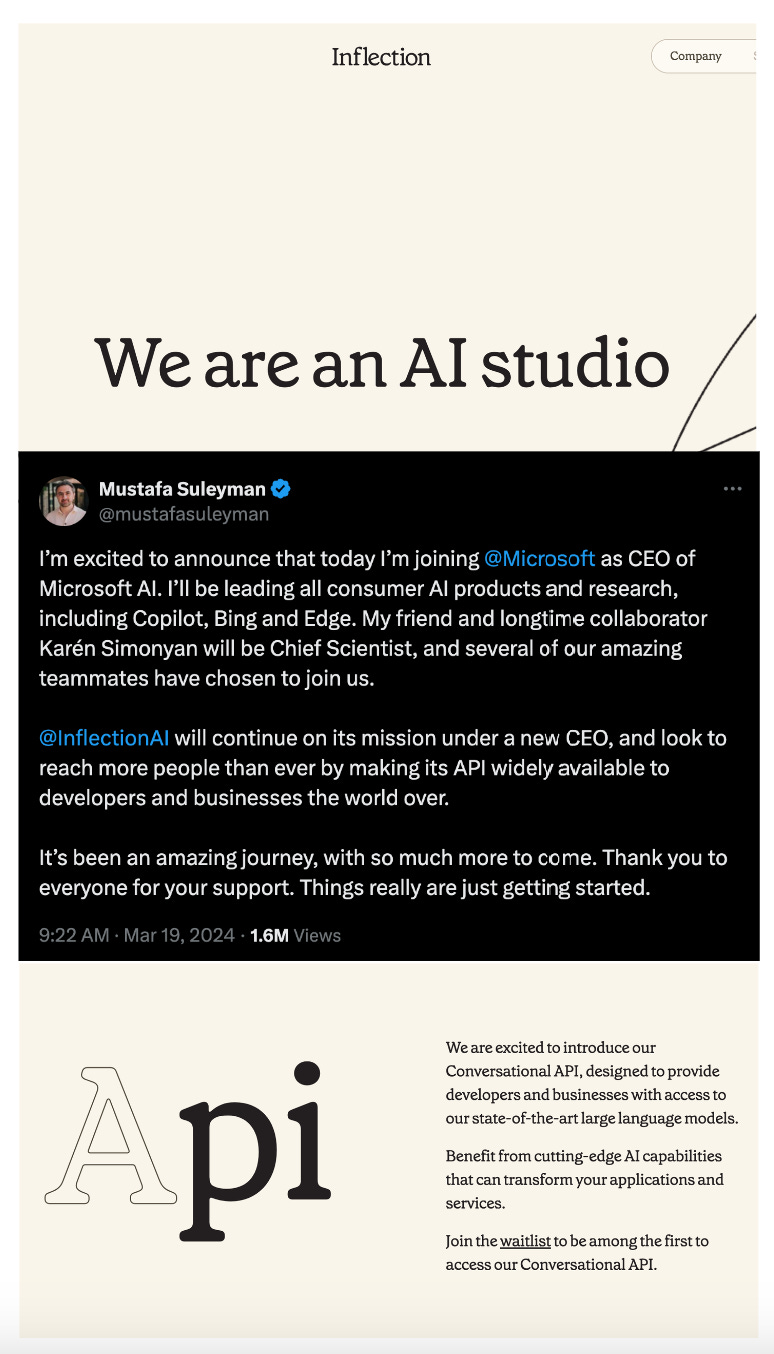
It seems Microsoft is moving its focus from OpenAI. They have just hired two of Inflection AI’s co-founders, Mustafa Suleyman and Karen Simonyan, to head Microsoft AI including products like Copilot, Bing, and Edge. The third co-founder Reid Hoffman will stay in Inflection AI’s Board. Here’s the chain of events and what happens next:
-
Microsoft invested $1.3 billion in Inflection AI in June 2023 to enable the company to develop its own AI supercomputer with 22,00 H100 GPUs.
-
Soon, Inflection AI released Infection 2 LLM which powers their empathetic chatbot Pi, very competitive with the GPT models in terms of performance on industry benchmarks. However, even with further Inflection iterations, it seems the company was not able to grab user traction.
-
Ripping apart Inflection, Microsoft has hired Inflection AI’s talent and now Inflection AI will pivot to focus on its AI Studio for developing custom generative AI models specifically tailored for commercial customers.
-
Also, Inflection 2.5 LLM will soon be available on Microsoft Azure so that the company’s technology can be more widely distributed and accessible to creators, developers, and businesses worldwide. This move is crucial for facilitating the development and fine-tuning of custom AI models for commercial clients as part of the AI studio service. Their API will also be up soon.
-
With the co-founders’ departure, Inflection AI welcomes Sean White as its new CEO. White, with his extensive experience in technology and innovation from companies like Mozilla and Nokia, along with board membership in several tech companies, will steer Inflection AI into this new chapter.
Sam Altman joined Lex Fridman yesterday on a podcast where they touched on a lot of topics including what exactly went inside OpenAI when Altman was ousted last year, the new Board members, Musk’s lawsuit, and OpenAI’s future releases. Here are all the important comments by Altman on the upcoming launches and his perspective on reaching AGI!
-
Before publicly releasing Sora, it needs to be able to be scaled first and also prevent it from generating deepfakes and misinformation. (39:29)
-
GPT-4 “sucks” relative to where we need to get to. The delta between GPT-5 and 4 will be the same as between GPT-4 and 3. (45:05)
-
We are on an exponential curve, we’ll look back relatively soon at GPT-4 like we look back at GPT-3 now. (47:53)
-
Sam Altman says they are not ready to talk about Project Q*. (1:03:14)
-
He confirmed the release of a new model this year, but it won’t be GPT-5. Before releasing GPT-5, OpenAI wants to release other products. (1:06:29)
-
Compute is gonna be the currency of the future. We should be investing heavily to make a lot more compute. (1:10:00)
-
In 5-10 years, people will program completely in natural language. (1:30:10)
-
On being asked about when AGI will be achieved, he expects by the end of this decade or maybe sooner than that, “we will have quite capable systems that we look at and say, wow, that’s really remarkable.” (1:32:25)
You can watch the full podcast here:
As we stated earlier, 2024 year will be significant in the development of general-purpose humanoid robots. Yesterday on the first day of Nvidia GTC, the company announced its foundational multimodal model, Project GR00T, for training robots to make them perform tasks by watching human demonstrators.
Leveraging Project GR00T, Apptronik trained its robot Apollo and released its demo where Apollo smoothly puts vegetables in a blender and hands over a glass of juice to the human engineer. The robot uses cameras and sensors to understand how to hold things and how its hands are positioned. This information helps Apollo learn a set of actions, like grabbing or moving things smoothly. Based on rules created by neural network visuomotor policies, which help Apollo figure out how to move and act in ways that seem natural, Apollo decides when to use these actions.
Apollo’s demo still doesn’t quite reach the level of sophistication seen in Figure’s robots which combines voice communication and reasoning capabilities powered by OpenAI’s tech. This capability surely makes the Figure’s robots more impressive and useful for wider applications. However, Nvidia’s Project GR00T should be able to incorporate these capabilities in Apollo which would then follow instructions in natural language and communicate just like a human assistant.
As AI advances to train these humanoid robots, they signal the impending practical application as well! Mercedes has started piloting Apollo to deploy them in the Mercedes-Benz manufacturing facility. While the specifics of the deal are not disclosed, Mercedes plans to use the Apollo robots to automate low-skill, physically demanding, repetitive yet essential tasks like moving items from one point to another, replacing labor that is easy to automate without immediately replacing human workers in a significant way.

Very soon, probably by this year-end, we might see humanoid robots not only becoming commonplace in industrial settings but also in other service areas where intricate reasoning capabilities along with dextrous motion are required.
Fine-tuning language models to our specific use cases has been a challenging and costly endeavor requiring extensive resources and technical expertise. Fireworks has just launched a new fine-tuning service, making it easier and more affordable to customize language models. It stands out by offering rapid iteration and deployment capabilities, along with competitive pricing. It’s designed to seamlessly integrate with Fireworks’ high-speed inference platform for a smoother and faster experience for customizing models to specific use cases.
Key Highlights:
-
Fireworks provides a frictionless experience for users by hosting fine-tuned models on the same serverless setup as their base models. This ensures that fine-tuned models remain speedy, with inference rates up to 300 tokens per second.
-
Fireworks does not impose additional fees for using fine-tuned models. You will pay exactly the same amount as for the base model. Since existing platforms charge 2x the cost to serve fine-tuned models, your cost would be cut by half or more along with higher inference speed.
-
The platform’s design allows for nearly instant deployment of tuned models, which can be ready for use in about a minute, eliminating the wait times typically associated with GPU boot-up.
-
You have the flexibility to deploy and compare up to 100 fine-tuned models simultaneously and swap them into live services, without incurring extra deployment costs. There’s no cost to deploying fine-tuned models, you’ll only pay for the traffic used.
-
It supports fine-tuning for 10 models. Fireworks doesn’t charge additional service fees for fine-tuning, it charges only per token of training data. With models with up to 16B parameters, the price is $0.50 per 1M tokens, and models ranging from 16.1B to 80B parameters are priced at $3.00 per 1M tokens. This makes fine-tuning more accessible to a wider range of projects and budgets.

-
Multi-Model Sessions by LM Studio: Load and prompt multiple local LLMs simultaneously, and use the API for constructing networks or pipelines where LLMs can interact with one another. It introduces a new JSON mode for output format constraints and supports diverse configurations including presets and JSON schemas.
-
AIApply: Automate your job search with AI. AIApply offers a suite of AI-powered tools to streamline the job application process for job seekers, including generating job-specific cover letters, resumes, and follow-up emails, practicing for interviews by generating mock interviews, AI-generated professional headshots, resume language translation, and more.
-
EdgeTrace: It enhances real-world video understanding by allowing users to search, analyze, and annotate vast amounts of video footage quickly and efficiently. It provides capabilities like semantic search, real-time event detection, automated annotations, and video analytics, to make video data easily accessible and actionable for various industries.
-
Coat of arms: Voice AI platform for developers to create, test, and deploy voice-bots quickly, reducing development time from months to minutes. It stands out with its features such as turbo latency optimizations for real-time interactions, proprietary endpointing to intelligently handle interruptions, the ability to scale to 1 million+ concurrent calls and extensive multilingual support.
😍 Enjoying so far, TWEET NOW to share with your friends!
-
In the future, when something suddenly becomes extremely valuable people will say it’s the new GPU. ~
Pedro Domingos -
agi was created by god; the timelines are determined by the members of technical staff ~
-
Chatbots will never become big because we (humans) are bad at asking good questions
Even with AGI, most people wouldn’t know what to ask
Whoever can get LLMs to do stuff for us without chat as the main interface will likely win. (Chat still needed but as an auxiliary feature) ~
Sully
That’s all for today! See you tomorrow with more such AI-filled content.
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!
PS: I curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!



















































































































































































































































































































































































































































