


Today’s top AI Highlights:
-
Resemble AI’s voice cloning tool requires even shorter audio sample than OpenAI’s Voice Engine
-
OpenAI violates YouTube’s terms by using a million hours+ of videos for training GPT-4
-
A study says more the AI agents, better the LLM’s performance
-
Perplexity-like search engine powered by Cohere’s LLM
& so much more!
Read time: 3 mins
Resemble AI has rolled out Rapid Voice Cloning which makes creating high-quality voice clones a matter of seconds. By reducing the need for long audio samples to a mere 10 seconds, this technology makes voice cloning more accessible to a wider range of users. What’s particularly intriguing is its ability to retain accents and subtle nuances in the voice with impressive accuracy.
Key Highlights:
-
Rapid and Accessible: Utilizes cutting-edge algorithms to analyze and replicate unique characteristics of the source voice, requiring as little as 10 seconds to 1 minute of audio sample.
-
Accent Retention: Faithfully mimics the unique intonations, pronunciations, and cadences of the speaker’s accent.
-
Speed: Generates voice clones within seconds for rapid iteration and deployment in your projects.
-
Comparison: Demonstrates notably better performance over other state-of-the-art models like Microsoft’s VALL-E and XTTS-v2, on voice prompts that these models haven’t encountered during training.
Voice Prompt:
Text:
“at its base, raider one is a four-wheel drive polaris, MVRS 700, that controllers can operate nearly one thousand yards away.”
They look like AI:
Microsoft VALL-E:
XTTS-2:
Training models like GPT-4 require a huge amount of high-quality data. It’s like the more a child reads, the better his knowledge is. However, the industry is broadly facing a diminishing pool of training data as what could be used has already been used. To overcome this, companies like OpenAI, Google, and Meta have used publicly available data without authorization, landing themselves in copyright infringement waters.
A report by the New York Times says that OpenAI, in search of training data for its GPT-4, transcribed over a million hours of YouTube videos using its Whisper audio transcription model. Greg Brockman, OpenAI’s president, was directly involved in collecting videos for this purpose. This position of OpenAI is more clear from an interview with YouTube’s CEO Neal Mohan and Bloomberg.
Key Highlights:
-
Mohan said he “has no information” on whether OpenAI used YouTube data to train its AI models. Mohan highlighted the lack of direct information on the matter, urging for direct inquiries to be made to OpenAI.
-
He pointed out that downloading YouTube content like transcripts or video bits without authorization would violate YouTube’s Terms of Service (TOS).
-
Mohan clarified that while certain elements of YouTube content, such as video titles, channel names, or creator names, can be scraped for broader accessibility on the web, other data like transcripts or video bits cannot be used without violating the TOS.
-
Google spokesperson Matt Bryant told The Verge in an email the company has “seen unconfirmed reports” of OpenAI’s activity, and that “both our robots.txt files and TOS prohibit unauthorized scraping or downloading of YouTube content.”
-
Even Google used YouTube data to train Gemini but “in accordance with TOS or individual contracts” suggesting that there are legitimate pathways for utilizing YouTube data.
-
Meta also bumped against the limits of good training data availability, after going through “almost available English-language book, essay, poem and news article on the internet,” and apparently considered acquisitions and licensing agreements for legal access to copyrighted materials. (Source)
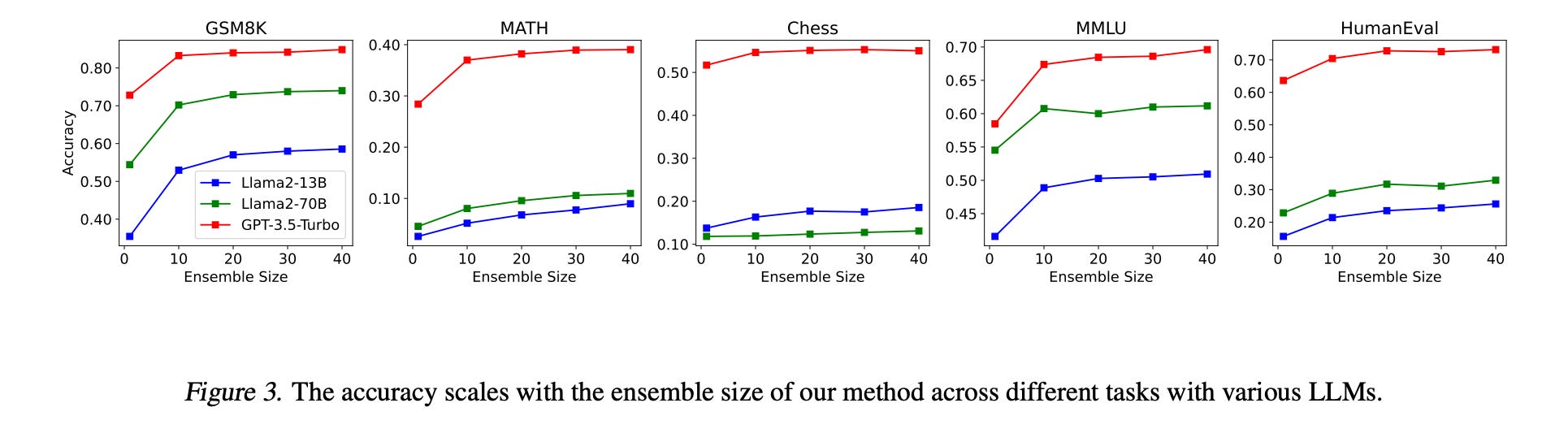
LLMs have been pushing the boundaries of what AI can do. Yet, they often stumble too intricate tasks. Even strategies like the Chain of Thought (CoT) reasoning, which attempts to mimic human-like reasoning processes, don’t always yield accurate results.
Against this backdrop, researchers at Tencent have porposed a surprisingly simple yet effective approach by increasing the number of agents working on a task and using a straightforward sampling-and-voting method to enhance LLM performance. It not only outperforms the CoT in consistency and reliability but also demonstrates a unique scalability by leveraging an ensemble of agents.
Key Highlights:
-
Sampling-and-Voting: A technique that scales up the number of agents, or “ensemble size,” to improve performance, by feeding the same task to multiple LLMs and using majority voting to decide on the best answer.
-
Performance Boost: Given any kind of task, increasing the number of agents consistently led to better performance. Smaller models like Llama 2-13B, when used in larger numbers, could match or even outperform bigger LLMs like Llama 2-70B and GPT-3.5-Turbo.
-
For More Complex Tasks: This straightforward approach can be combined with more sophisticated methods to push performance even further. This suggests that there’s untapped potential in existing models.
😍 Enjoying so far, share it with your friends!
-
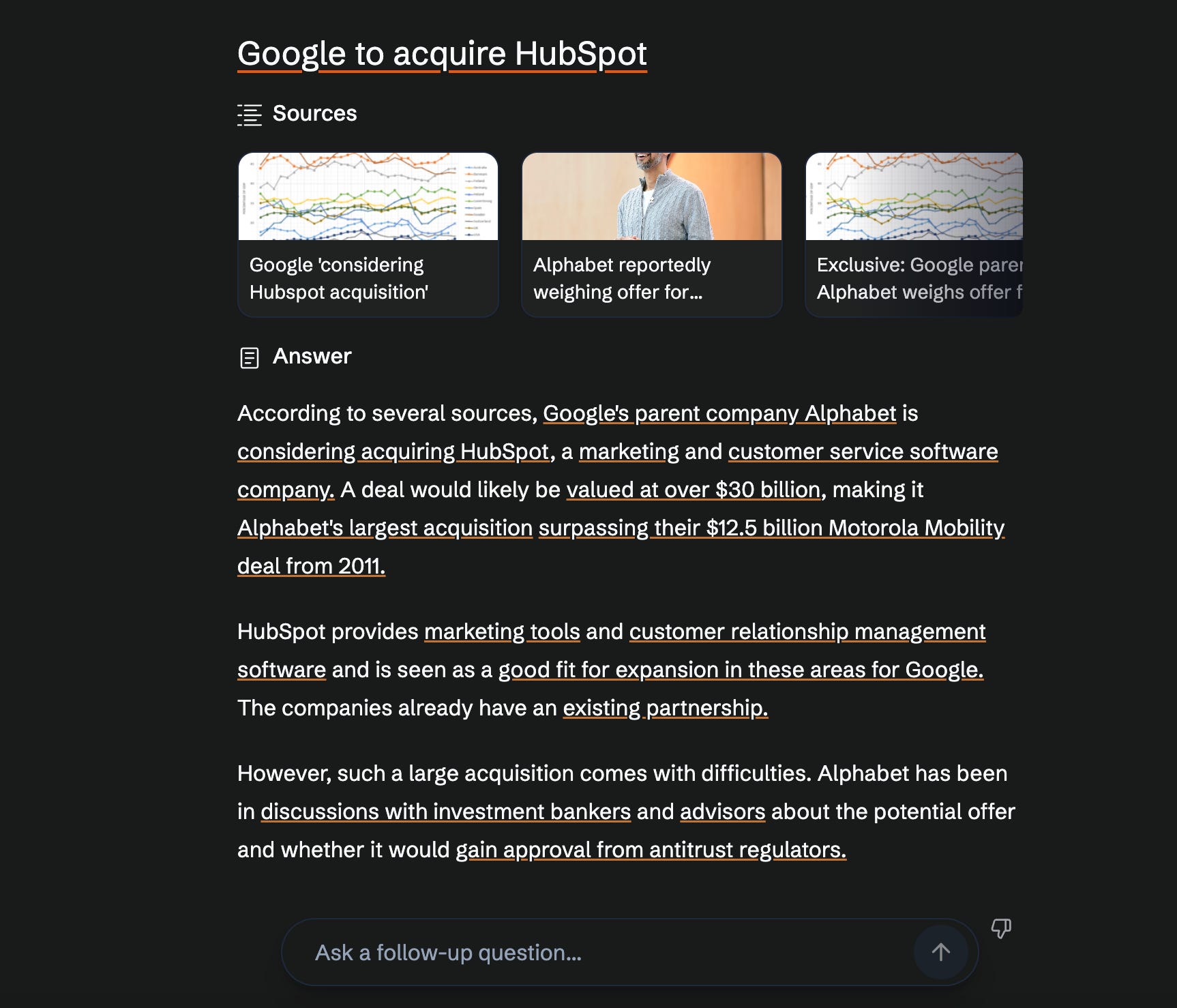
Complexity: A search engine that uses AI to answer questions. It is built on top of the Cohere AI platform and is designed to provide a fast and efficient way to find answers to your questions. Just like Perplexity AI, it also provides in-line citations and lets you ask follow-up questions.
-
Platypus: A toolkit to help data engineers and technical founders manage distributed and real-time data 10x faster by organizing and connecting data across any stack in any format. It simplifies data management with automation for data discovery, management, and pipeline creation for business teams to access and utilize data more efficiently.
-
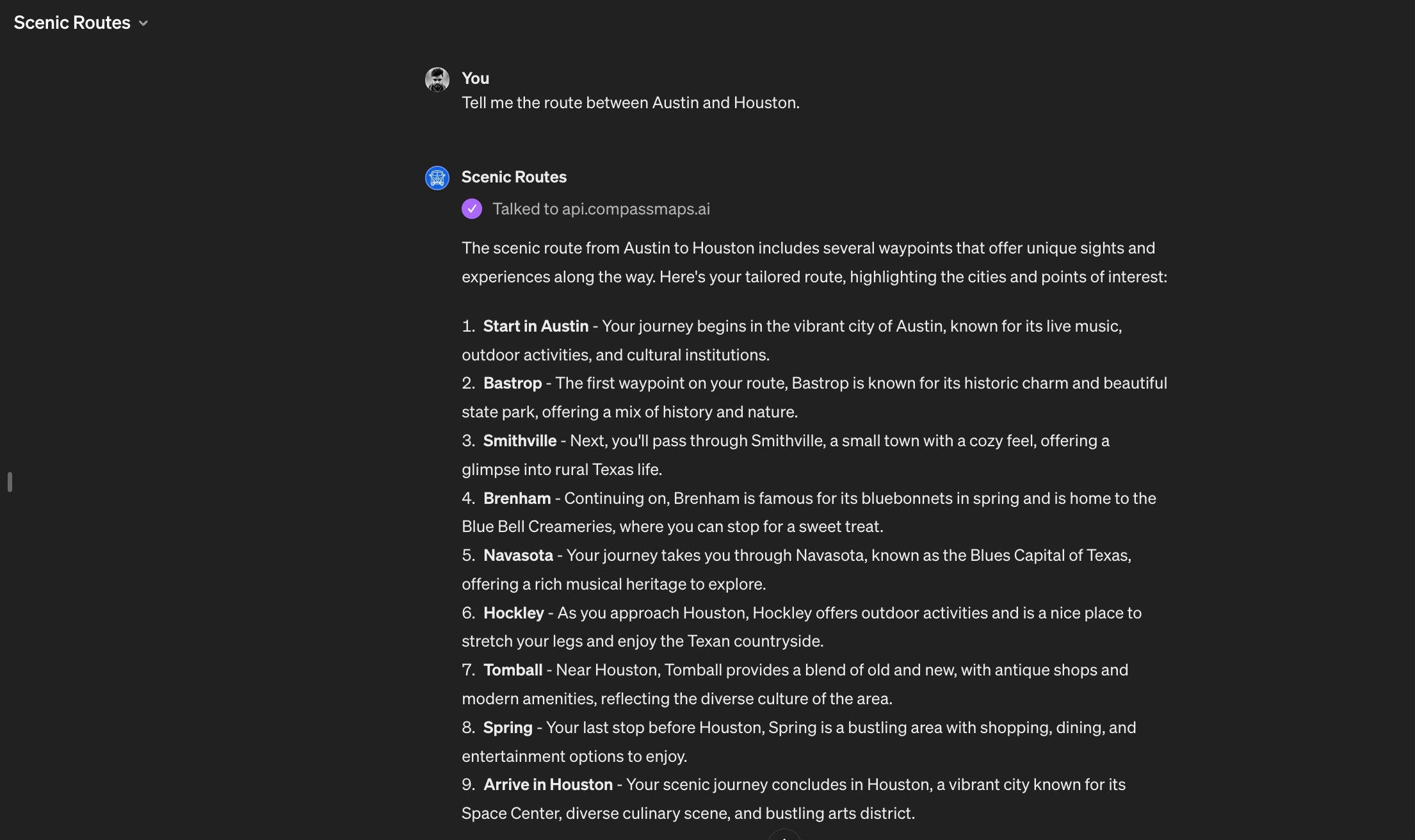
Scenic Routes GPT: Finds the most scenic route for your road trips or travels. If you give it a starting point and a destination, it can calculate a route that’s not just about reaching fast but also enjoying beautiful landscapes and interesting places along the way.
-
TextCortex: Write with AI that speaks your voice. Text Cortex offers a customizable platform that learns and adapts to your unique writing style. It integrates with 50k+ apps for ingesting your knowledge base, can surf the web to tell you the latest trends, can learn a style and tone you want, and help you create content at scale.
-
AI consciousness is inevitable and girlfriend apps may be in the best position to solve it ~
Bindu Reddy -
movies are going to become video games and video games are going to become something unimaginably better ~
Sam Altman
That’s all for today! See you tomorrow with more such AI-filled content.
⚡️ Follow me on Twitter @Saboo_Shubham for lightning-fast AI updates and never miss what’s trending!
PS: I curate this AI newsletter every day for FREE, your support is what keeps me going. If you find value in what you read, share it with your friends by clicking the share button below!




















































































































































































































































































































































































































































